Replace any voice with any other voice.
Drop in a clip. Pick a target voice. Get the same words back, in that voice. Runs entirely on your machine — nothing uploads, nothing logs.
Free to use. No account. No telemetry.
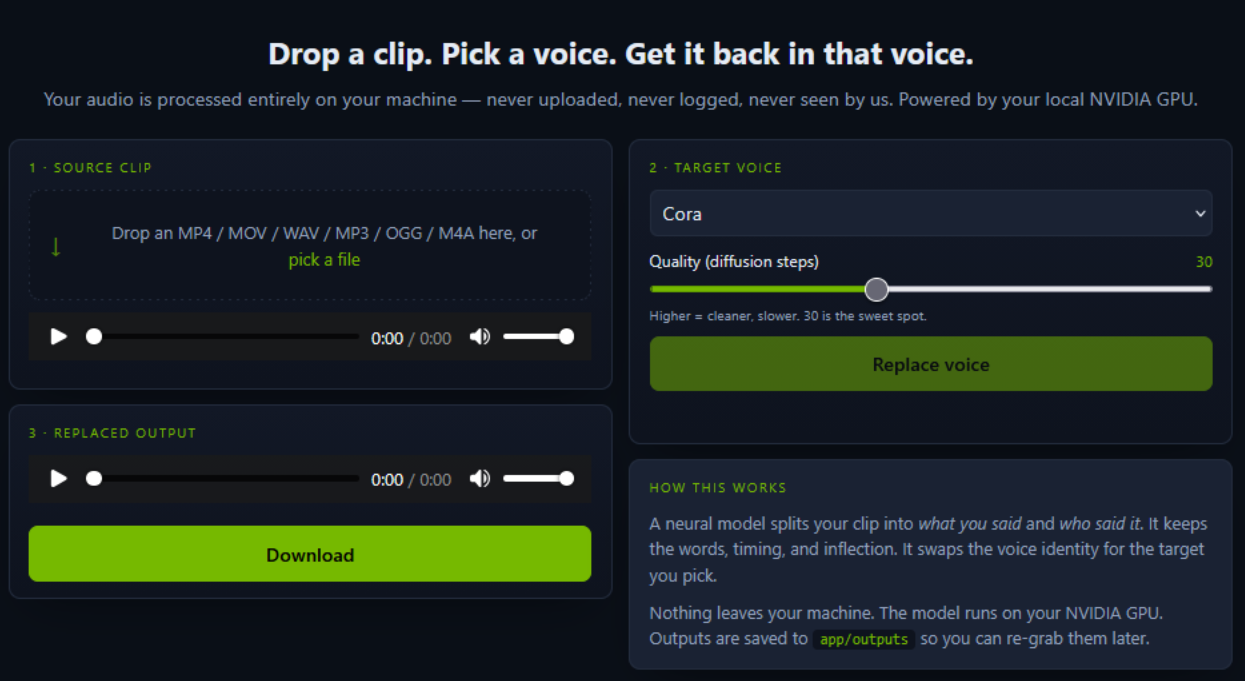
The local interface — runs in your browser at localhost:7860 after launch.
Drop a clip
Audio or video — MP3, MP4, WAV, OGG, M4A. Up to a few minutes.
Pick a target voice
Choose from the bundled voices, or add your own reference clip to clone any voice.
Get it back
Same words, same timing, same delivery — in the target voice. Save the WAV.
What's preserved, what's swapped
A neural model splits your clip into what was said and who said it. It keeps the words, the timing, the rising and falling of your delivery — everything that makes a performance yours. It swaps the vocal identity for the target.
- Kept from source: words, timing, inflection contour, emotional delivery
- Replaced from target: vocal timbre, pitch range, voice identity
Download
Extract anywhere. Double-click start.bat. The UI opens in your browser.
System requirements
- Windows 10 or 11 (64-bit)
- NVIDIA GPU with at least 6 GB VRAM (RTX 3060 or better recommended)
- CUDA-capable driver (the installer checks and prompts you to update if needed)
- ~10 GB free disk space
What about Mac / Linux / no GPU?
The model is too heavy to run on CPU at usable speed. If you don't have an NVIDIA GPU, the browser-based DSP version works on any device — slider-based pitch and formant shifting, no install, runs entirely in your tab. Quality ceiling is lower than the neural tool, but for many cases it's enough.
Common questions
How do I add my own target voice?
Drop any .wav / .mp3 clip into the refs/ folder inside the bundle.
5+ seconds of clean speech is ideal. Reload the page (or just reopen the UI) and it'll show up in the dropdown.
Where do the converted outputs go?
app/outputs/ inside the bundle folder. They stay there until you delete them — you can re-download
them from the UI any time. The output filename includes the source name, target voice name, and parameters used.
Why 8.4 GB?
Bundled neural model weights (~3 GB), the PyTorch + CUDA runtime to execute them on your GPU (~5 GB), and the engine code. Everything is included so you never need an internet connection after download. Comparable to Stable Diffusion WebUI or LM Studio with a model.
Does it work without internet after install?
Yes. The bundle ships with all model weights, and the tool is configured for offline use by default.
The HuggingFace model loader is told HF_HUB_OFFLINE=1 at launch.
How long does a conversion take?
Roughly 2× real-time on an RTX 4070 or better — a 30-second clip takes about 15 seconds. Older cards (RTX 3060, 3070) are 3–5× real-time. The first conversion of a session is a few seconds slower while models warm up on the GPU.
Multiple files? Batch mode?
v0.1 is one file at a time through the UI. Batch mode is on the roadmap. For now, the CLI under
seed-vc/inference_v2.py accepts a single file per call and is scriptable from PowerShell or bash.
I'm getting an error — what do I do?
- "CUDA error: no kernel image" — your NVIDIA driver is too old. Update from nvidia.com/drivers.
- "Port 7860 already in use" — another app is using the port. Close it, or change the port at the top of
app/server.py(VR_PORT). - Antivirus quarantines start.bat — some AVs flag unsigned
.batlaunchers. Add the bundle folder to your AV's exclusions, or run the python directly:seed-vc\venv\Scripts\python.exe app\server.py. - "Out of memory" on a 6 GB card — try a shorter source clip (under 30 seconds) or lower the diffusion-steps slider in the UI to 15–20.
Use it well
Voice conversion is a powerful tool. Don't use it to clone someone's voice without their permission. Don't make people appear to say things they didn't say. Don't use it to deceive, harass, defame, or impersonate. Many jurisdictions have laws around voice cloning and audio impersonation — find out what applies where you live.
Use it on your own voice. Use it with public-domain or licensed reference voices. Use it with explicit consent from anyone whose voice you're working with. The tool itself stays out of your way; the responsibility for what you do with it is yours.
Privacy
Everything runs locally on your machine. Your audio is never uploaded. We don't host inference, we don't log anything, and the tool has no network calls except to check for updates (which you can disable).